파이썬을 통해 빅데이터 분석을 하기 전에,
파이썬의 기초 문법을 확실히 알아두자.
1. 라이브러리 Import

사용하고싶은 라이브러리가 있으면 import를 하면된다.
import (라이브러리 이름) 으로 코딩하면된다.
추가로 알아두면 좋은것이, import (라이브러리 이름) as (편한이름) 으로 설정하면,
(편한이름).sqrt() , (편한이름).pow() 로 사용할수있다.
EX) numpy->np , pandas ->pd
2. for 문

기본 형태는 for x in range()이다.
x는 데이터 이름을 , range()는 범위를 설정한다.
range(10)은 0~9까지 하나씩돈다 . 증분의 디폴트는 +1이다.
증분을 설정하고싶다면, range(시작, 끝, 증분) 으로 사용하면된다.
3. if문
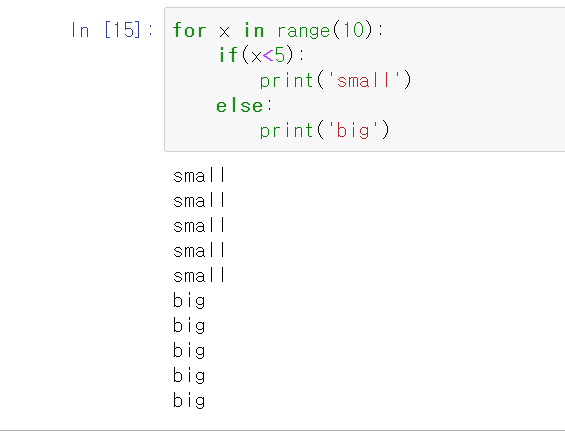
다른 언어와 다를게 없다. if 와 else문으로 조건을통해 분기를 나눌수있다.
다만 들여쓰기가 매우중요하다. 들여쓰기가 틀리면, 오류나 원하지않는 결과가 출력된다.
4. 함수(메소드) 작성

함수 선언은 def 로 선언한다.
def 이름(파라미터) : 로 작성만하면 끝이다.
함수를 불러올때도, 이름(파라미터)을 부르면 끝이다.
물론, 반환값 (return)을 지켜주는건 당연하다.
5. 클래스 만들기

기본 클래스 선언은, class (클래스명) : 으로 선언을한다.
클래스를 선언하고, 인스턴스화 (객체만들기)를 해주는 메소드가, __init__이다.
또한, self 파라미터가 눈에띠는데 자기참조를 하겠다는 뜻이다. 실제론 파라미터를 입력하지않는다.
인스턴스화 __init__ 말고,
+, *, -< /, % : __add__, __mul__, __sub__, truediv__, __mod__
<. <=, ==, !=, <, >= : __lt__, __le__, __eq__, __ne__, __get__, __ge__
[], in, len, str : __getitem__, __contains__, __len__, __str__
여러가지 기능을 지원한다.
6.다양한 자료구조 (리스트, 튜플 , 딕셔너리, 셋)
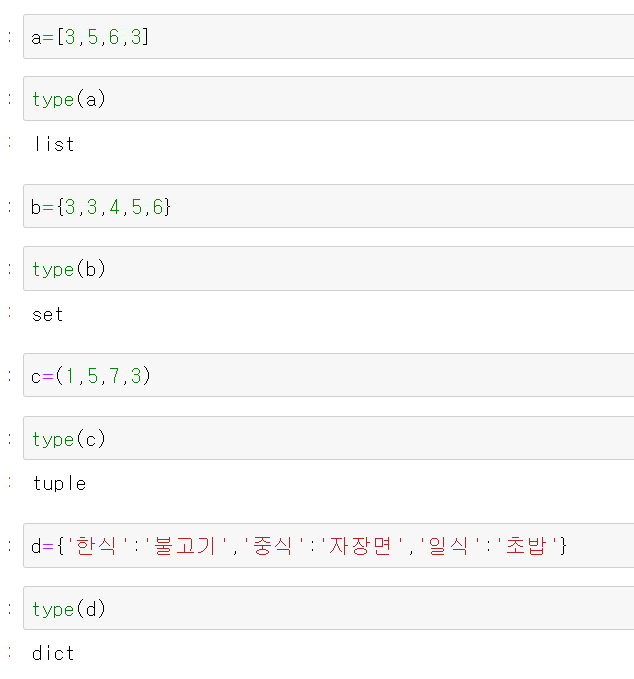
파이썬의 강점.. 자료구조를 선언안해도 기호를통한 규격만 맞춰주면 자동선언이된다
리스트를 사용-> [ ] 괄호를 사용
세트를 사용 -> { } 괄호를 사용
튜플을 사용 -> ( ) 괄호를 사용
딕셔너리를 사용 -> {key: value} 형식으로 사용
리스트의 기능
- 마지막에 원소 추가 : append(값)
- 특정 위치에 원소 추가 : insert(위치, 값)
- 특정 위치 원소 삭제 : pop(위치)
- 특정 원소 삭제 : remove(값)
튜플 vs 리스트
튜플의 범위는 정적이고, 리스트의 범위는 동적이다.
튜플은 크기가 정해져있고, 리스트는 파일이 추가될때마다 범위가 동적으로 커지고 작아진다.
세트(Set)는 중복을 알아서 제거해주는 배열이다.

중복으로 숫자를넣어도, 알아서 중복을 제거해주는 모습을 볼수있다.
딕셔너리
keys(), values(), items() -> 각각 키들을 반환, 밸류들을 반환, 키/밸류들을 반환하는 메소드
딕셔너리는 Key:Value 형식으로 저장한다. Java에 익숙하신분은 Map 이라고 생각하시면된다.
쉽게 생각해서, idx의 숫자가 Key로 바뀐다고 생각하면 쉽다.
그래서, 딕셔너리,map이 탐색,검색,삭제할때 O(1)의 선형시간이 난다.
'빅데이터 분석 > 파이썬' 카테고리의 다른 글
| 파이썬 머신러닝 :회귀모형 (0) | 2021.11.14 |
|---|---|
| 파이썬 맷플롯(Matplot) 라이브러리 (0) | 2021.10.25 |
| 파이썬 판다스(Pandas) 라이브러리 (0) | 2021.10.24 |
| 파이썬 넘파이(Numpy) 라이브러리 (0) | 2021.10.23 |
| 빅데이터 분석 시작하기 (Why?, 언어, 환경) (0) | 2021.10.22 |