본격적으로 머신러닝을 사용해볼것이다.
머신러닝시스템은 크게 2가지로 나뉜다.
지도학습 VS 비지도학습
지도학습 : 특성(Feature) 과 레이블(label)을 가지면서 머신러닝을 하는방식이다.
비지도학습: 훈련데이터에 특성들만 있는 레이블이없는 형태로 머신러닝하는방식.
지도학습의 학습형태는 또 2가지로나뉩니다.
분류 VS 회귀
지도학습중에서 회귀를 먼저 다뤄볼것인데요.
회귀(Regression)는 수치형데이터를 머신러닝할때 사용합니다.
수치형 데이터란?
사람들의 몸무게, 키, 나이 , 혈압처럼 0~N만큼 수치를 가지는 데이터입니다.
분류는(Classification) 범주형 데이터를 머신러닝할때 사용합니다.
범주형 데이터란?
사람들의 혈액형, 성별 또는 꽃의 종류 와같이 뚜렷하게 분류할수있는 데이터입니다.
이번 포스팅은 지도학습의 선형회귀모형을 살펴보겠습니다.

선형회귀 라이브러리를 호출합시다.
호출하려면, sklearn.linear_model 패키지에서 LinearRegression을 불러옵니다.
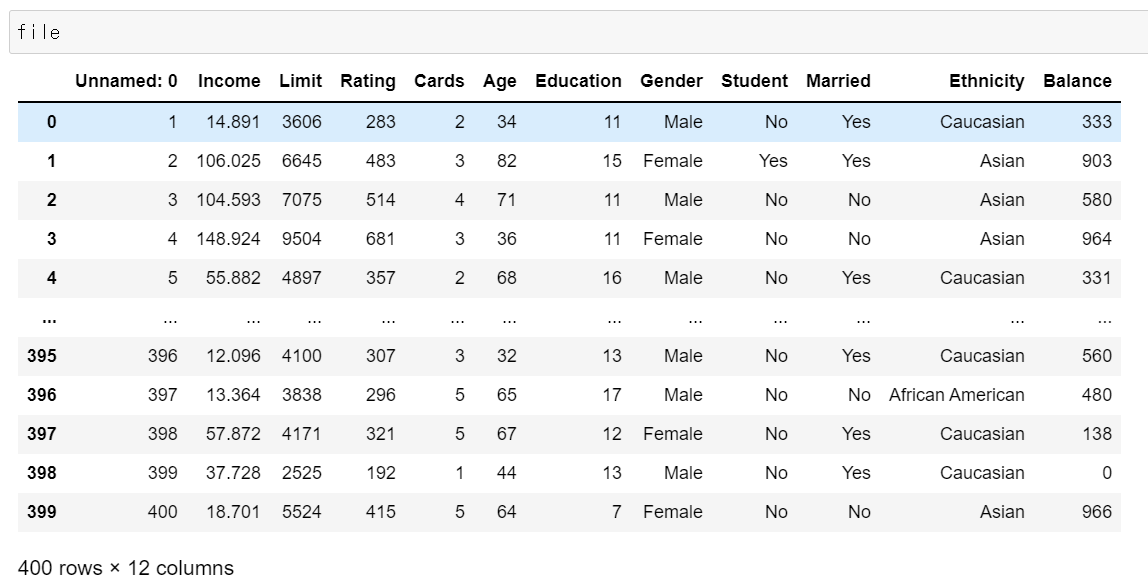
선형회귀모델로 머신러닝을 진행해볼 빅데이터입니다.
예시로, 특성(X좌표)을 Rating으로 label(y좌표)을 Balance로 잡아보겠습니다.

선형회귀모델 reg를 선언합니다.
선형회귀모델 reg를 훈련시키는 메소드는 fit() 메소드입니다.
reg,fit(X,Y)로 훈련을 시킵시다.

자 reg.coef_와 reg.intercept_ 요게 무엇일까요?
아까 저희가 회귀는 수치형데이터를 예측하기위해 사용한다고하엿죠?
선형회귀모델은 하나의 직선을그려, 수지형데이터를 평균을 예측합니다.
저 2개의 값으로 하나의 직선식이완성이됩니다.
y= reg.intercept_ + reg.coef_ x 의 직선이완성됩니다.
-> y= -390.84 + 2.566x
조금 시각화 해볼까요?
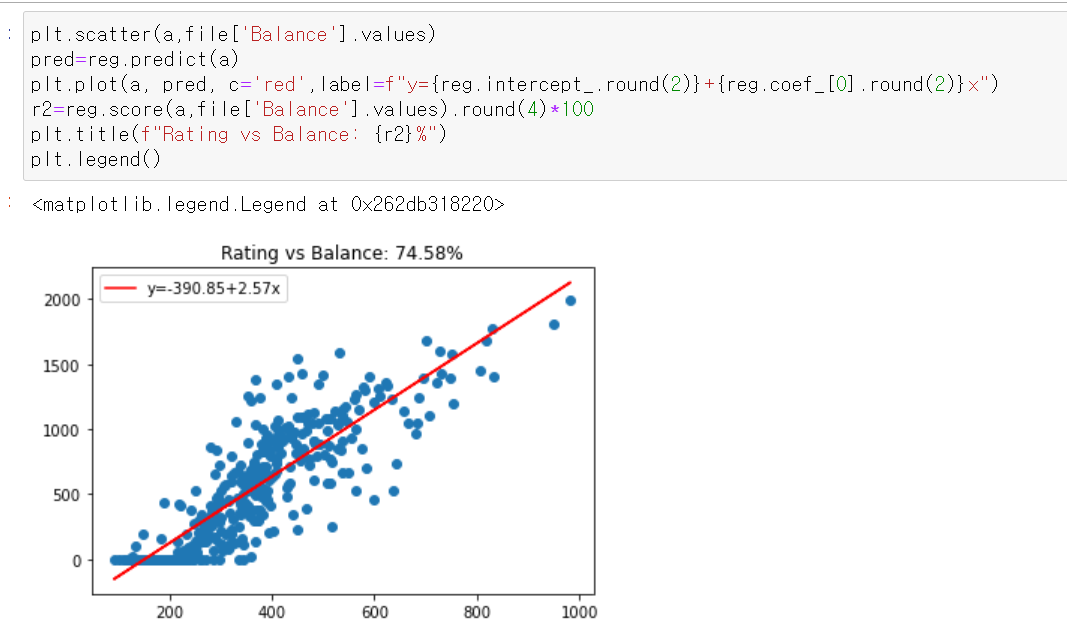
파란점은 실제로 훈련에 사용된 데이터들이고
빨간선은 우리가 사용한 선형회귀모델입니다.
이 데이터가 정확도를 알 수 있는 메소드가있는데, reg.score() 인 결정계수입니다.
결정계수(R^2)가 74.58%니, 이 선형회귀모델은 74,58퍼센트 믿을만 하다 라고 이해하시면 될것입니다.

데이터를 훈련시켰으면 실제로 예측을해봐야죠!
예측하기위한 메소드 predict()를 사용합니다.
각각 Rating 500,740, 240 의 예측결과로 Balance 892,1508,225 가 나온걸 확인할 수 있습니다.
그런데 이 결정계수가 무조건 높다고 좋을까요? 그렇진 않습니다.

왼쪽 그림이 선형회귀모델로 훈련데이터 정확도 70프로를 가지고있습니다.
오른쪽 그림은 데이터를 아~~주 정확하게 훈련시킨 예시입니다.
곡선으로 표현하는만큼 모델을 아주 빡세게 훈련시킬수있습니다.
정확도가 98프로나 됩니다.
하지만 , 테스트 모델을 볼까요?
왼쪽그림의 테스트모델의 정확도는 74프로를 가지고있습니다.
반면, 오른쪽그림의 테스트모델의 정확도가 0프로에 수렴합니다.
훈련데이터를 아~~주 세밀하게 훈련시켯는데, 테스트 데이터를 전혀 예측못하는현상을
과대적합(Overfitting)이라고합니다.
반면, 훈련데이터를 너~~무 대충 훈련시켜서 훈련이 제대로 안되는 현상을
과소적합(underfitting)이라고합니다.
지금까지 회귀모델로 수치형데이터들을 훈련시켜보았는데요.
다음 포스팅은, 빅데이터 범주형 데이터들을 훈련시키는 모델 분류(Classification)을 다뤄보겠습니다.
'빅데이터 분석 > 파이썬' 카테고리의 다른 글
| 파이썬 : 웹 스크래퍼 만들기(2) (0) | 2023.01.18 |
|---|---|
| 파이썬 : 웹 스크래퍼 만들기 (1) (0) | 2023.01.18 |
| 파이썬 맷플롯(Matplot) 라이브러리 (0) | 2021.10.25 |
| 파이썬 판다스(Pandas) 라이브러리 (0) | 2021.10.24 |
| 파이썬 넘파이(Numpy) 라이브러리 (0) | 2021.10.23 |